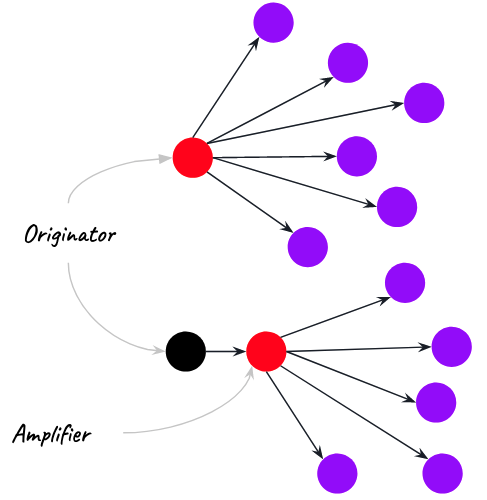
Originators vs. Amplifiers
Who is responsible for spreading misinformation on Twitter?

Matthew R. DeVerna,
Rachith Aiyappa, Diogo Pacheco,
John Bryden, Filippo Menczer

Originators and Amplifiers
- Twitter data assumes all retweets are of the original poster
- This renders amplifiers completely invisible
Who is actually driving the spread of misinformation?
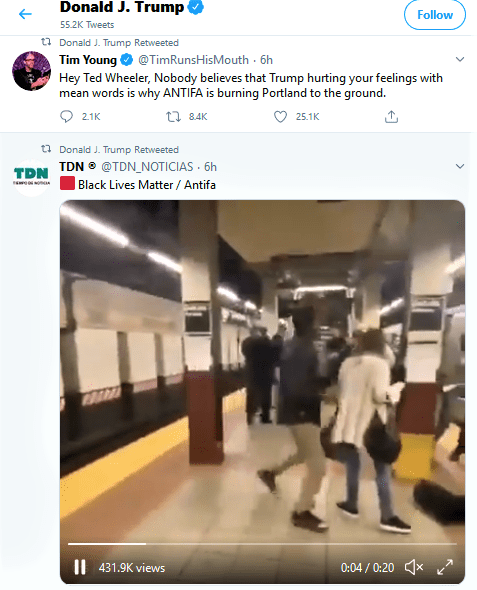
- Trumps retweet of this video shows us why this is a problem
- API data from this tweet will attribute zero retweets to Trump

General approach
- Gather a bunch of data
- 4 months (Apr. — Jul. 2020)
- Tweets contain a low-credibility source (filtered stream)
- 100 most shared from: Shao et al. (2018), Grinberg et al. (2019), Pennycook and Rand (2019), Bovet and Makse (2019)

-
Amplifiers analysis
- Look for amplifiers within individual cascades (spoiler alert, we find them)
-
Measure their influence at the
network level
- Determine the best way to find superspreaders of misinformation
- Explore behavior of amplifiers vs. originators

- Test how well we can predict who will become a superspreaders of misinformation

-
Explore
account status
of superspreaders
- active / suspended / verified

Reconstructing cascades
(Randomly sample 5k cascades from each month)
- Naive: Twitter data only
- Reconstructed: via probabilistic diffusion inference
- Nodes → users
- Weights → number of retweets
- How edges are drawn
Two versions of retweet networks for each month
Both versions (weighted-directed)
Difference between versions

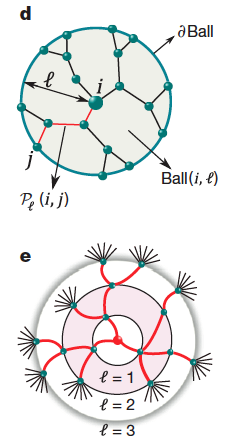
Probabilistic diffusion inference
... utilized to infer how cascades actually unfolded
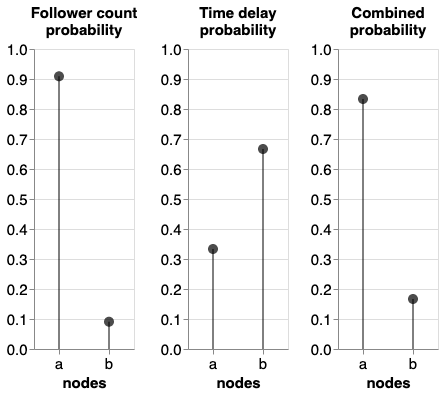
Two simple assumptions → two probability distributions
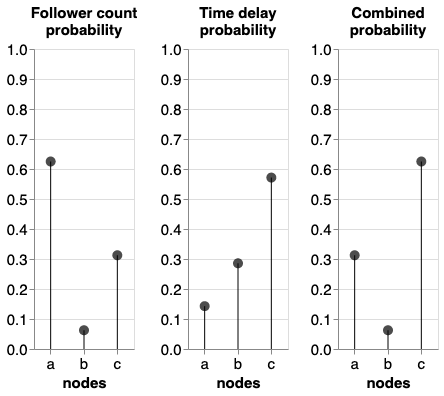
Follower-count probability

Users with more followers will be more likely to be retweeted
(probability proportional to number of followers)
Time-delay probability

Accounts more recently involved are more likely to be retweeted
(power-law probability distribution)
Toy example
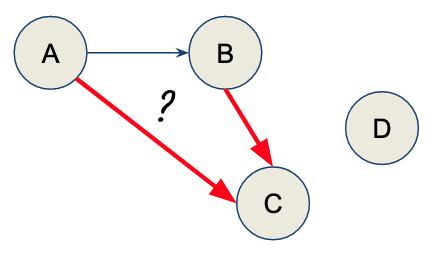
- Followers: a > c > b
- Time delay (recency): c < b < a
Choosing parent of c
Choosing parent of d
This method is probabilistic...
... so we create 1,000 versions of each month's network
- 1k reconstructed networks
- 1 naive network

- 1k reconstructed networks
- 1 naive network

- 1k reconstructed networks
- 1 naive network

- 1k reconstructed networks
- 1 naive network
How can we find amplifiers?
Two criteria to define an amplifier of a cascade

domination
- A user “dominates” cascade c when earning ≥ 𝜽 proportion of a cascade's retweets
- 𝜽 with range [0,1] is the domination threshold

uncommon
- Number of retweets earned in c ≥ mean_rts(c) + one_std(c)
- Must earn most of a cascade's retweets (defined by 𝜽)
- Num. retweets earned needs to be out of the ordinary
Look for amplifiers in every cascade...
...for all versions of a month's network...
...at various domination threshold levels.
Proportion of cascades with amplifiers
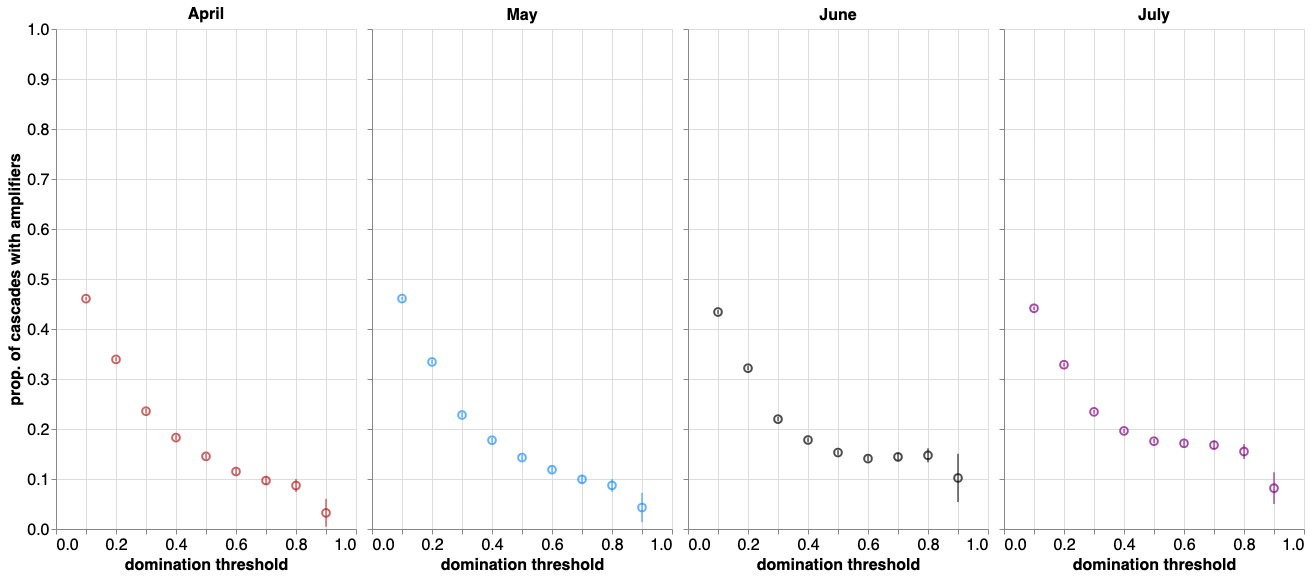
Substantial proportion of cascades contain amplifiers!
How influential are amplifiers within the misinformation network?
Dismantling analysis
Naive + recosntructed
- Node strength
- FIB index
Reconstructed only
- Sum of subtree sizes*
- Weighted page rank
- Collective Influence*
- Optimal*
Collective influence
Sum of subtress

Optimal
Greedily select a random account from set of nodes where…
Dismantling results
Why does using the reconstructed network lead to worse results?
Percentage of amplifiers who are also originators
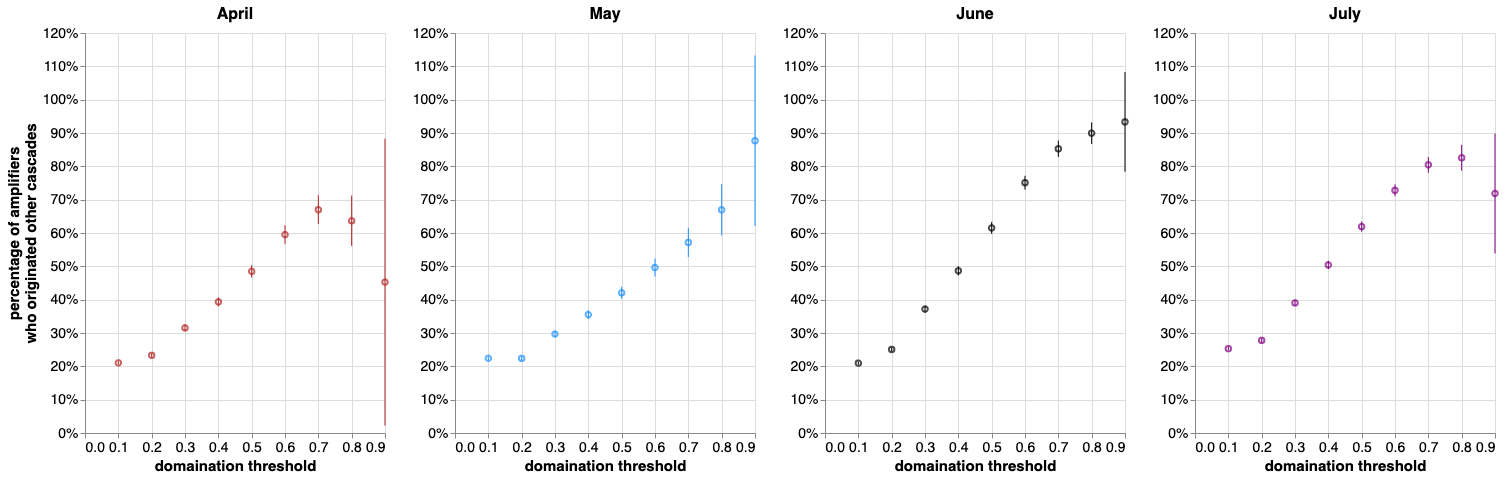
Originators are amplifying other originators!
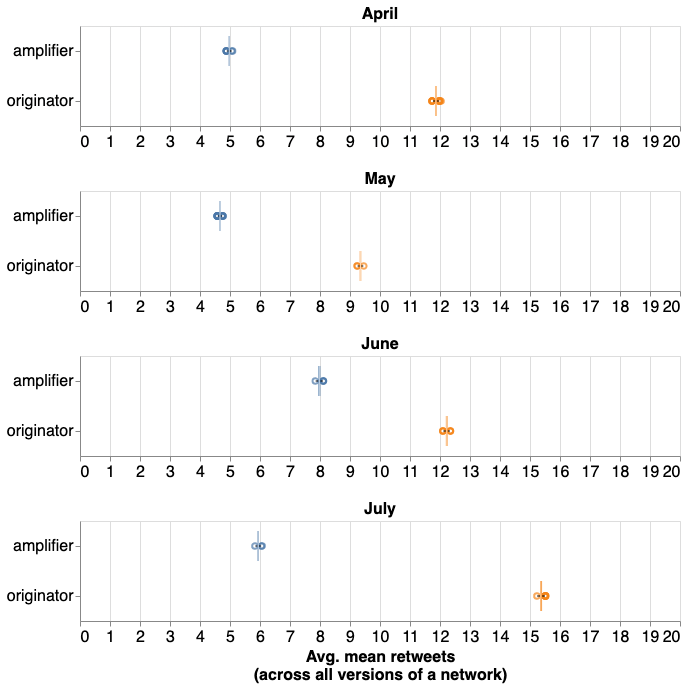
Originators get more retweets than non-originator amplifiers average!
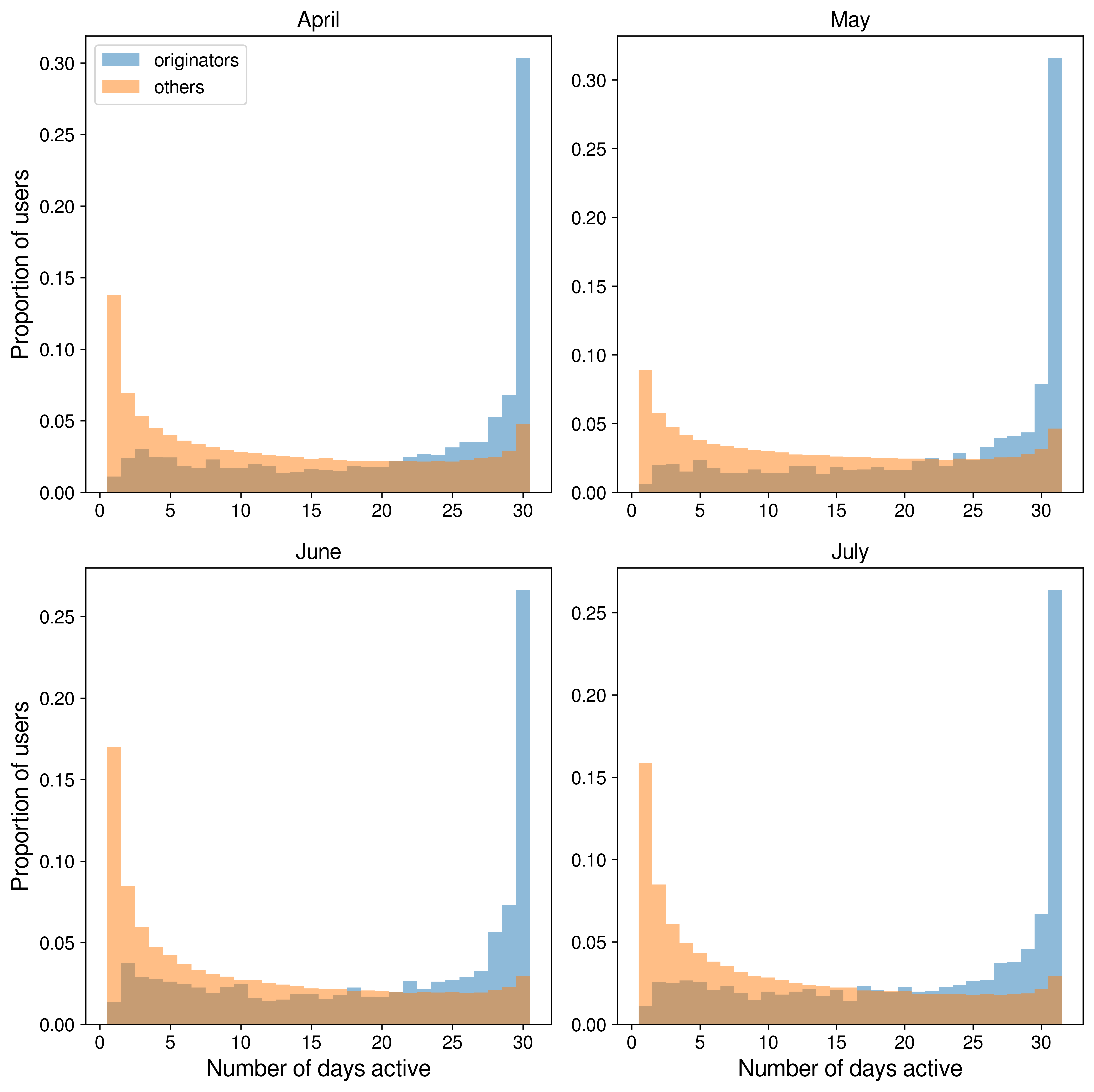
Originators are much more active than other users!
Can we predict who will become a superspreader?
- Measure the overlapping set of top ranked users for all metrics compared to the optimal
- Top 10, 50, 100, 1,000 users
Predicting superspreaders
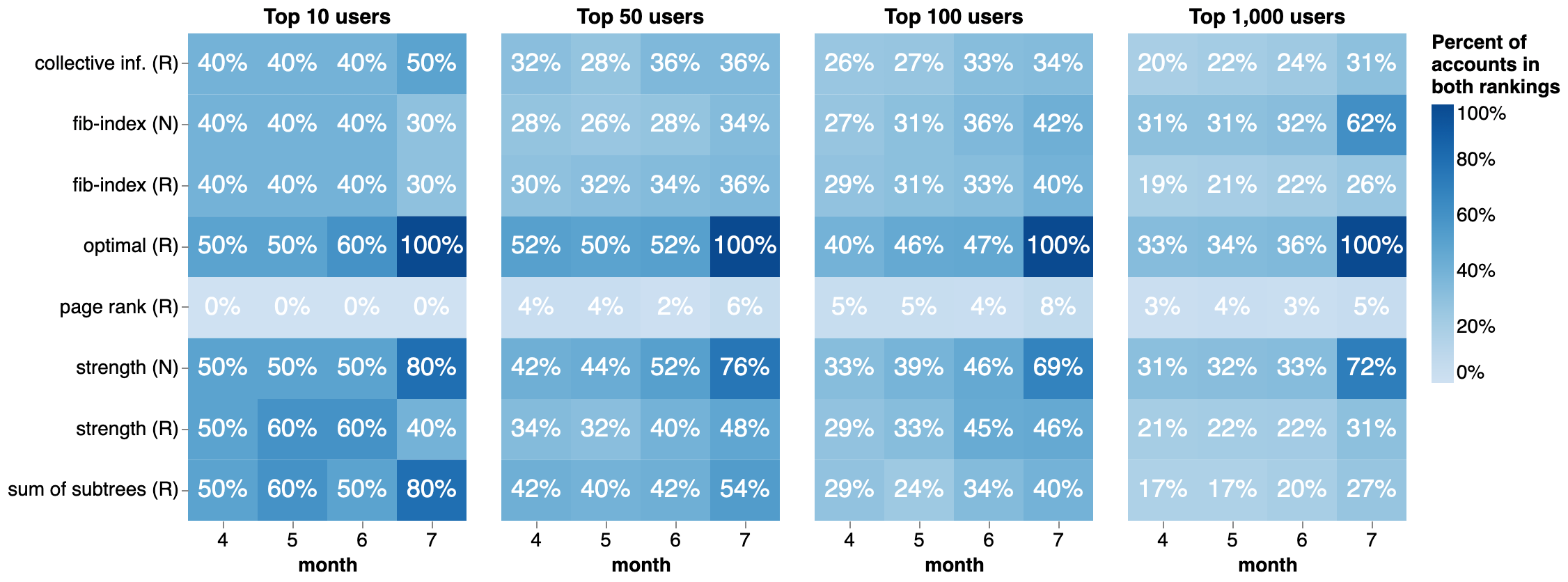
Most metrics do a decent job!
What is the status of these accounts two years later?
- Are they still tweeting?
- Are they verified?
- How many followers do they have?
Repulled account data for top 100 superspreaders in each month with V2 API (August 7 2022)
Account status of top 100 superspreaders
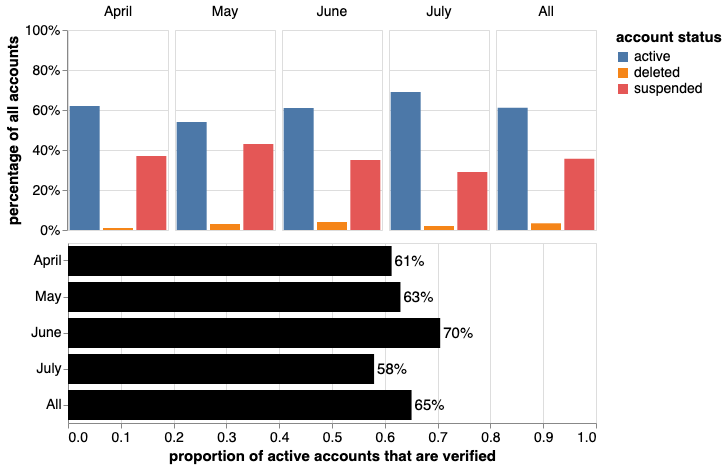
Most are still active and verified!
Number of followers by status
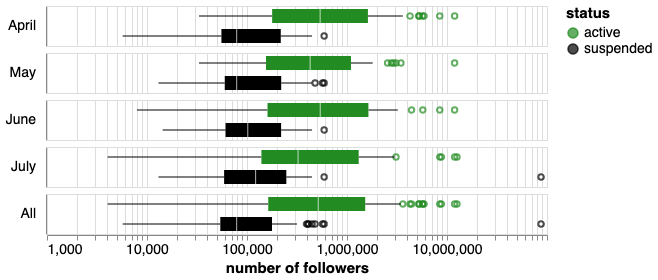
Accounts with more followers tend to still be active
What we learned...
- Amplifiers do exist...
- ...but they tend to be originators — who:
- Are much more active than everyone else
- Earn more retweets than non-originating amplifiers
- Superspreaders are not hard to find
- Tend to be verified
- Many are still active
- Those who are active have more followers than those who have been suspended



Rachith Aiyappa

Diogo Pachecho

John Bryden

Filippo Menczer