Fact-checking information from large language models can decrease headline discernment
Proceedings of the National Academy of Sciences (paper)

Matthew R. DeVerna, Harry Yaojun Yang, Kai-Cheng Yang, and Filippo Menczer
Observatory on Social Media, Indiana University Bloomington
matthewdeverna.com
How do people respond to fact-checking information generated by an LLM?
People are worried about LLMs...




So others are testing how to fight back...





But how do people respond to this information?
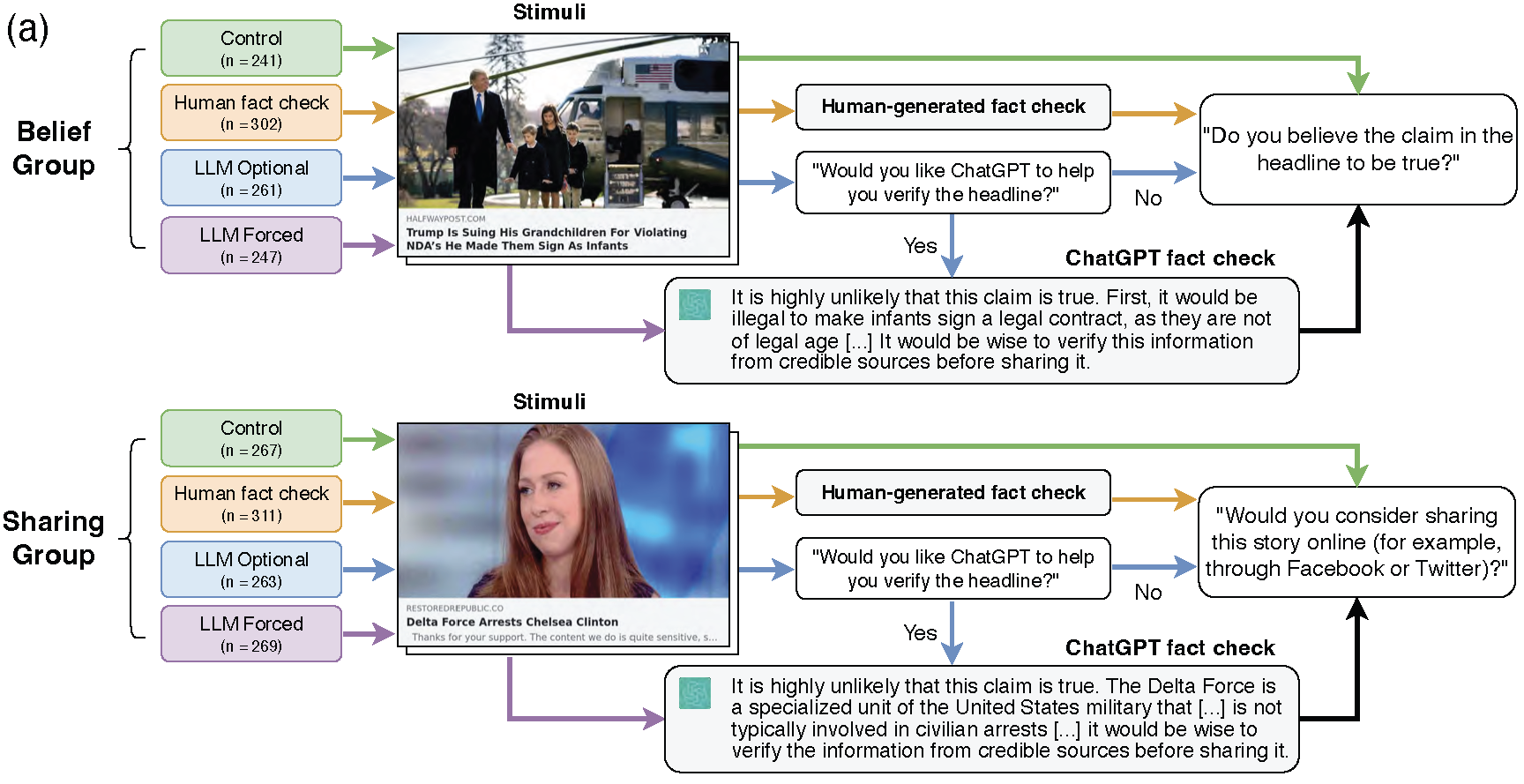
Experimental Design
💻 Online experiment ($n = 2,159$)
📰 40 true/false news headlines
🔴 Half pro-republican and 🔵 half pro-democrat
🤖 ChatGPT 3.5 fact-checking information
📏 Outcome variables: Belief vs. Intention to share
💊 Treatment: Forced vs. optional vs. control
What did we learn?

LLM accuracy
Pretty accurate for false headlines...

... not so great for true headlines.
Various fact-checking scenarios
|
True
and judged False
❌ |
True
and judged Unsure
❓ |
True
and judged True
✔ |
True | Headline Veracity |
|---|---|---|---|---|
|
False
and judged False
✔ |
False
and judged Unsure
❓ |
False
and judged True
❌ |
False | |
| True | Unsure | False | ||
| LLM judgment | ||||
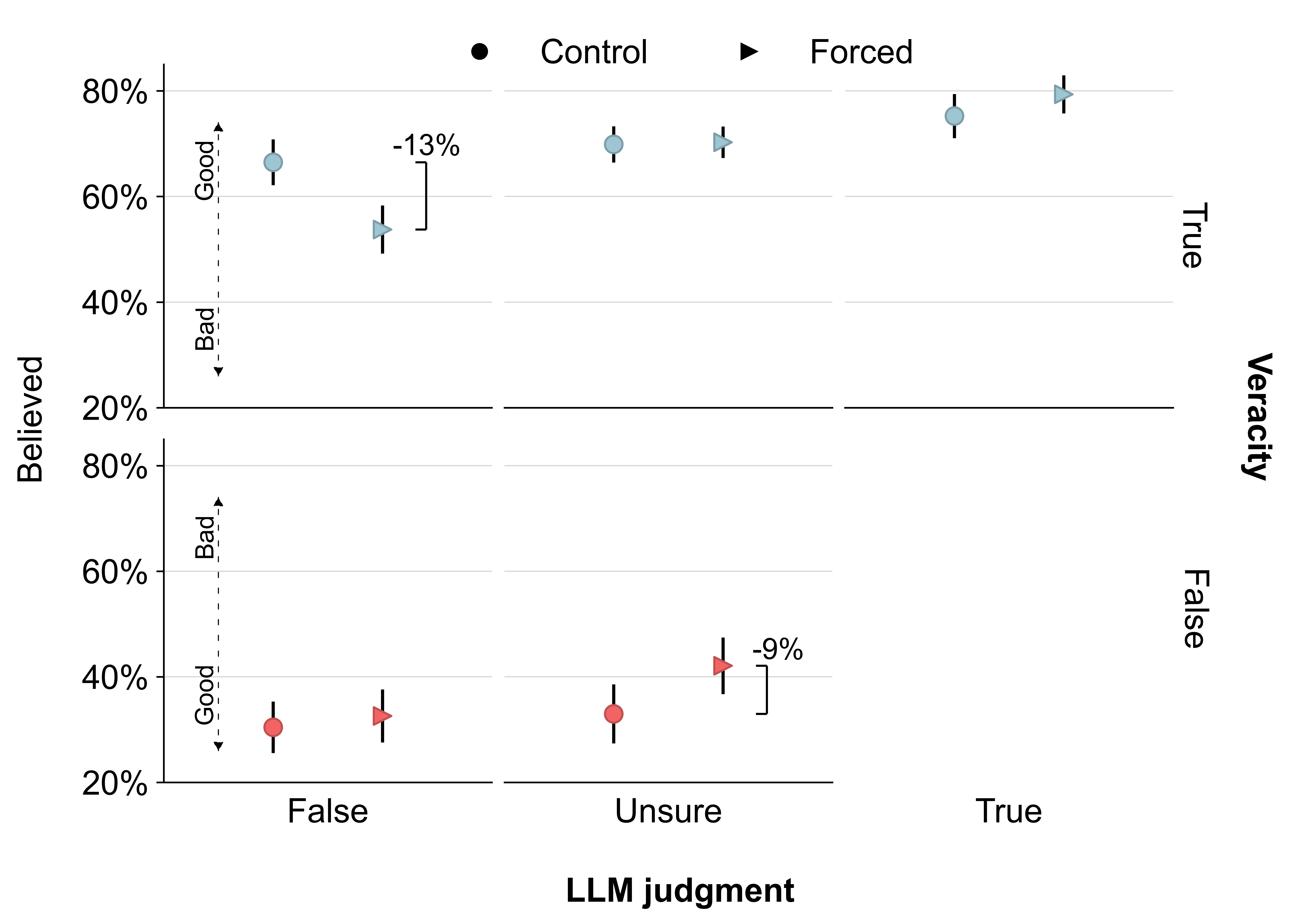
LLM fact checks reduced belief discernment
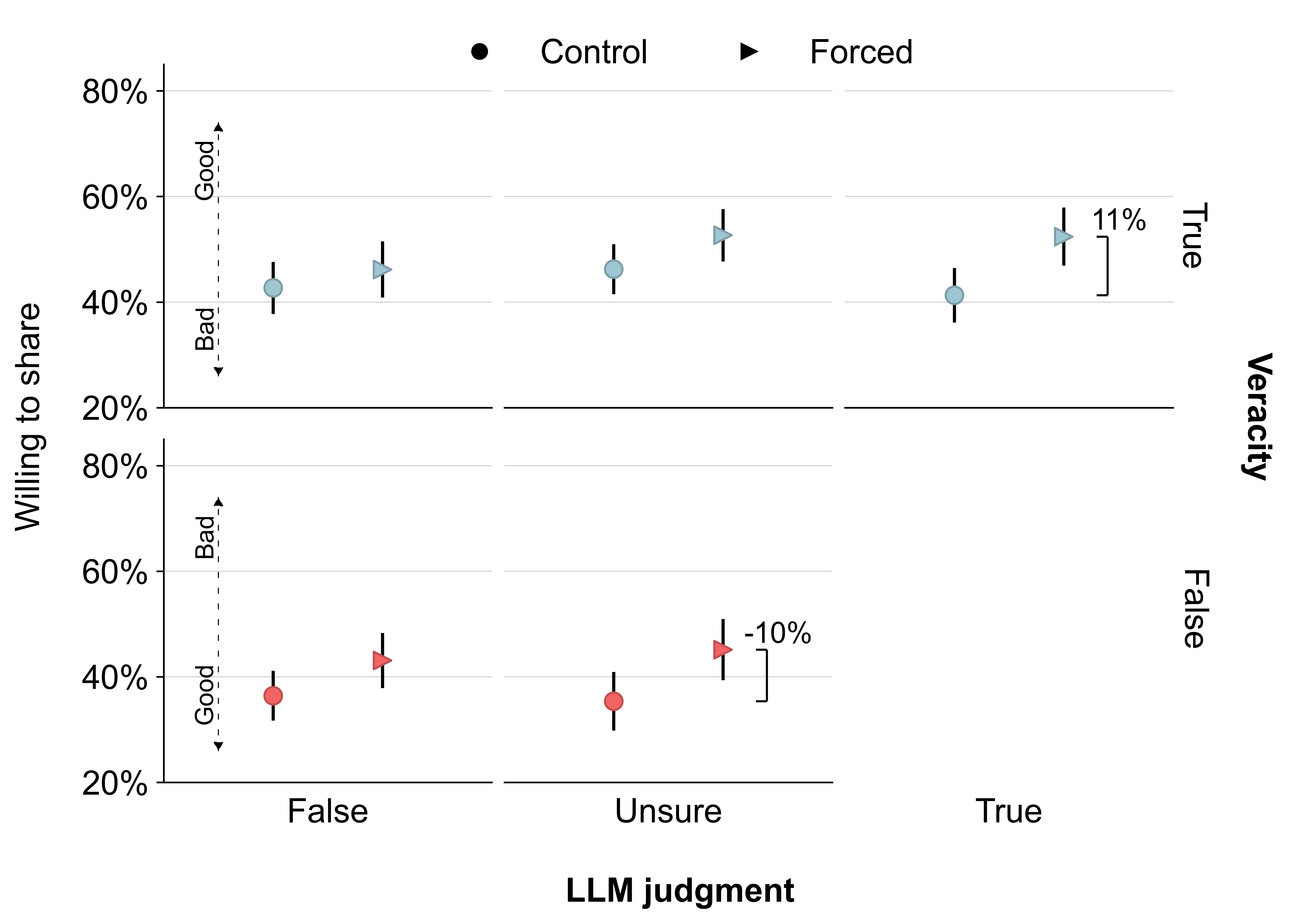
Mixed effects for sharing intentions
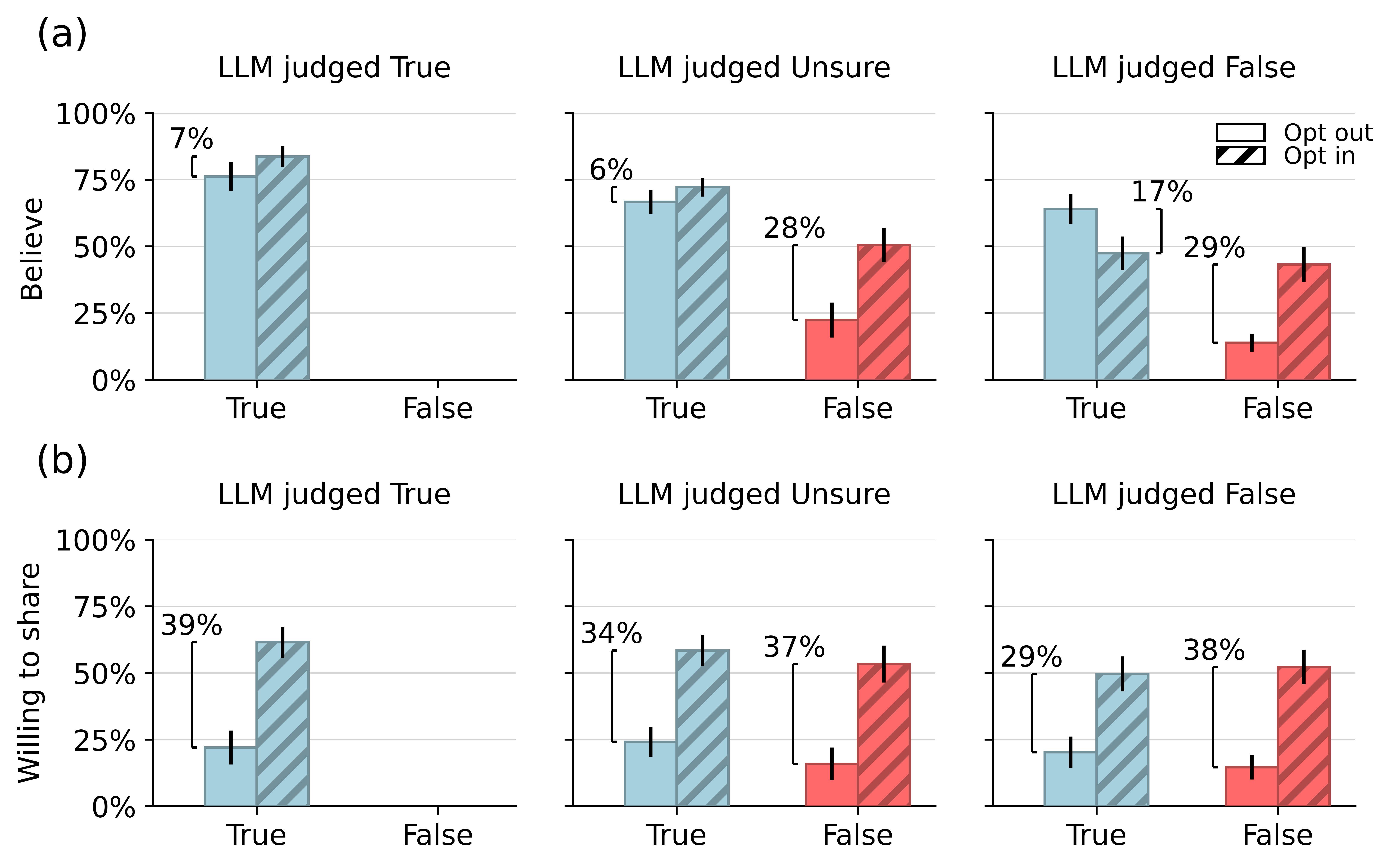
Optional results...
- Sharing more likely when choosing to view fact checks
- Belief more likely for False headlines accurately judged
Takeaway 1: Average discernment
Average discernment was not affected by LLM-generated fact checks... 🤖
... but human fact checks worked well (as expected). 👍

Takeaway 2: Fact-checking scenarios
⚠️ LLM fact checks reduced belief discernment in certain scenarios...
... and had mixed effects on sharing intentions. 🔄

Takeaway 3: Optional condition
Strong selection bias 🔍 for choosing to view fact checks...
...with evidence participants may be ignoring accurate fact checks of false headlines. 🚫

Does that mean LLMs should not be used for fact-checking? 🐘
No.
Instead, design systems thoughtfully... 🧠
🎯 Accuracy matters. (RAG systems are promising.)
📝 Prompt design/output matters. (Careful with uncertain responses.)
📰 Support accurate news. (Much more of it than false news.)
Questions?
Appendix
Opt-in distributions
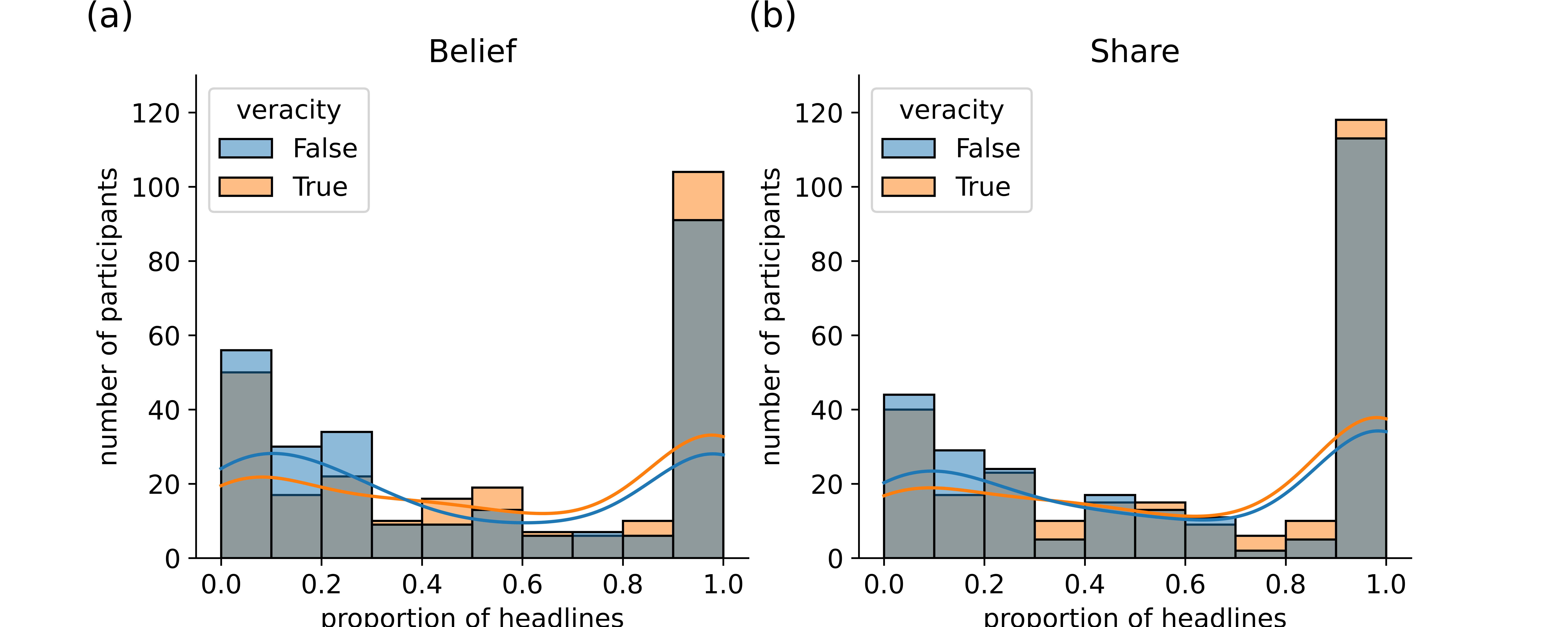
By group
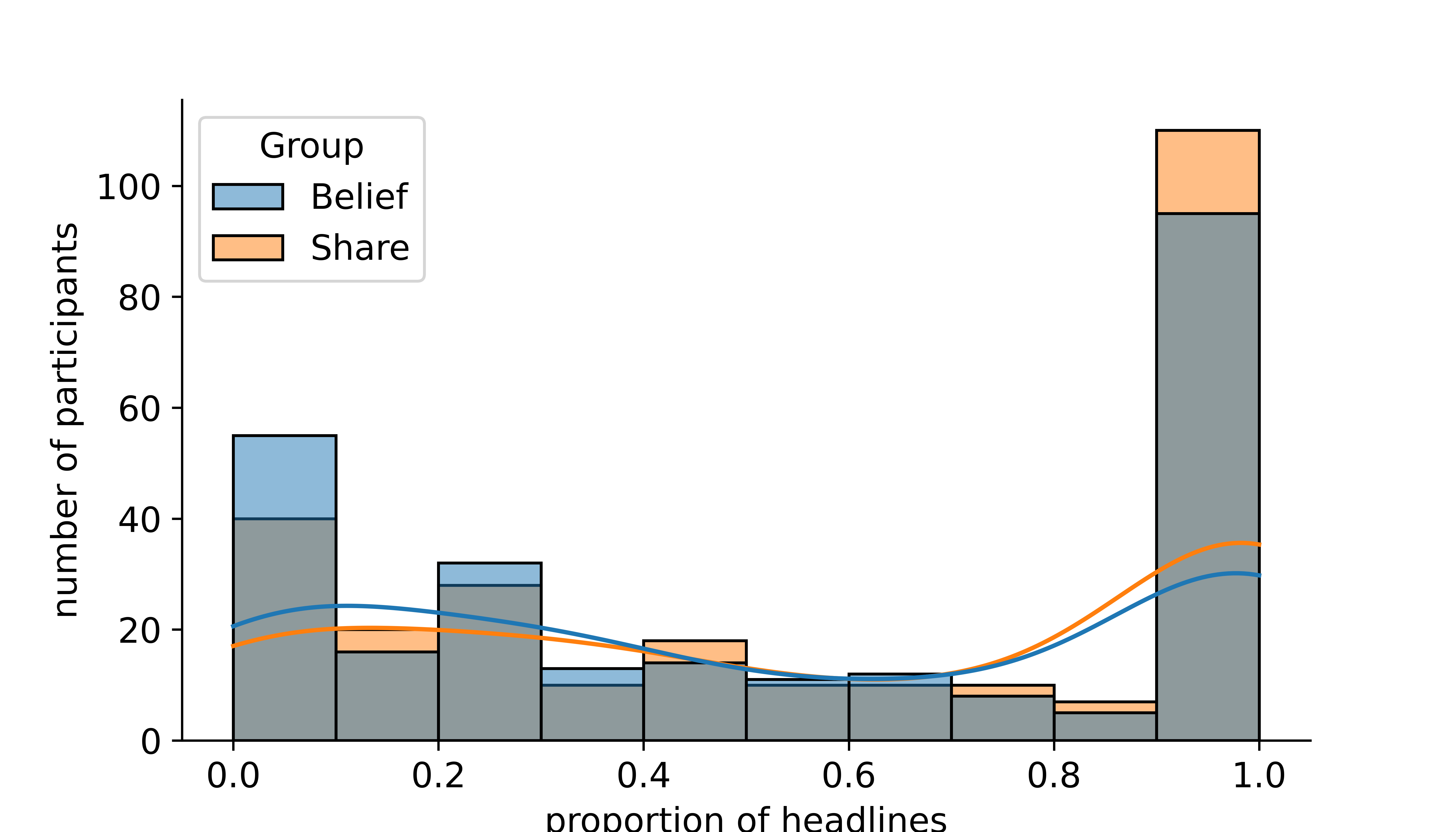
By group and veracity
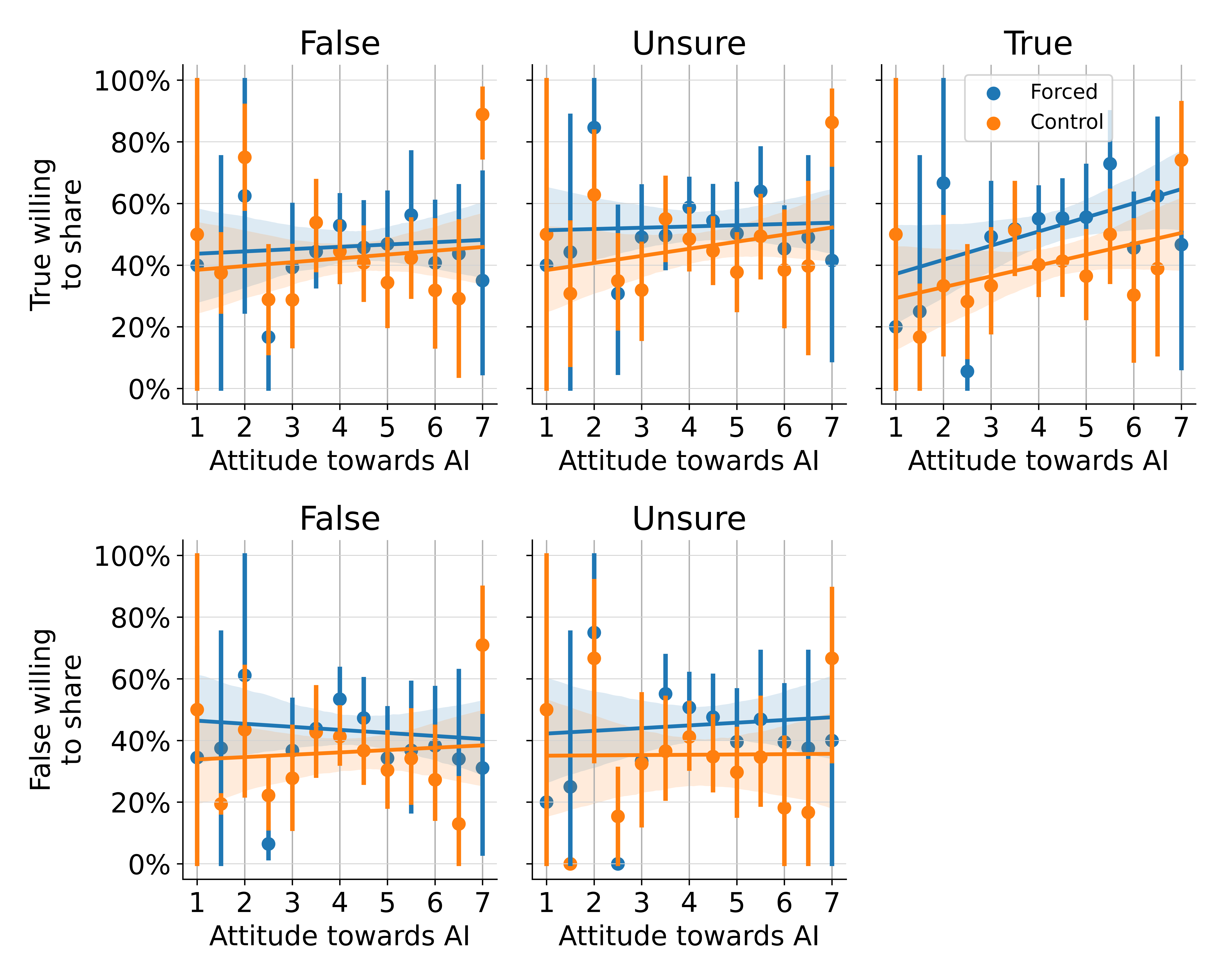
Attitude towards AI (ATAI)
Main effects (ATAI)
Fact-checking scenario (belief + ATAI)
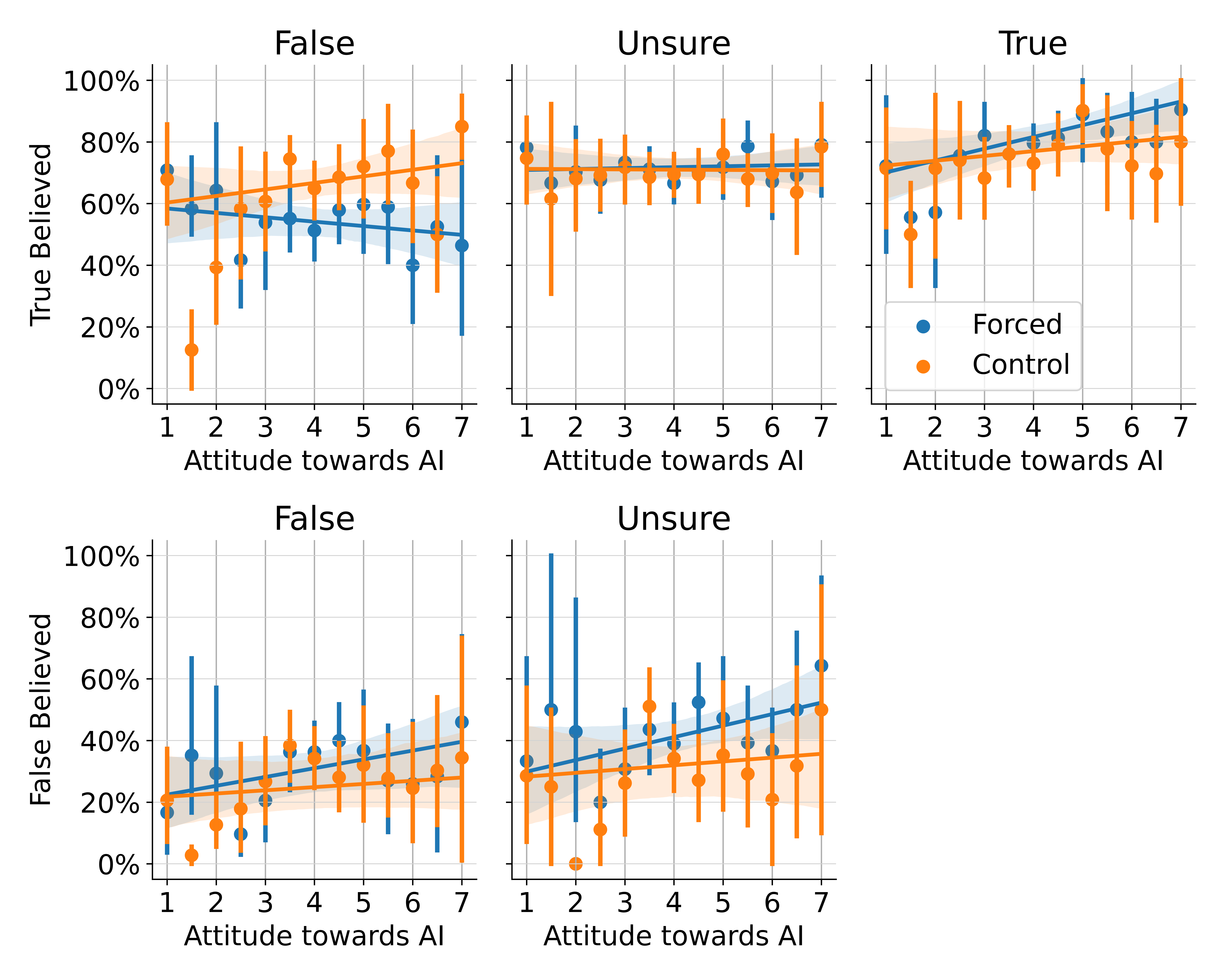
Fact-checking scenario (share + ATAI)
Headline congruency (with participant ideology)
Main effects (congruency)
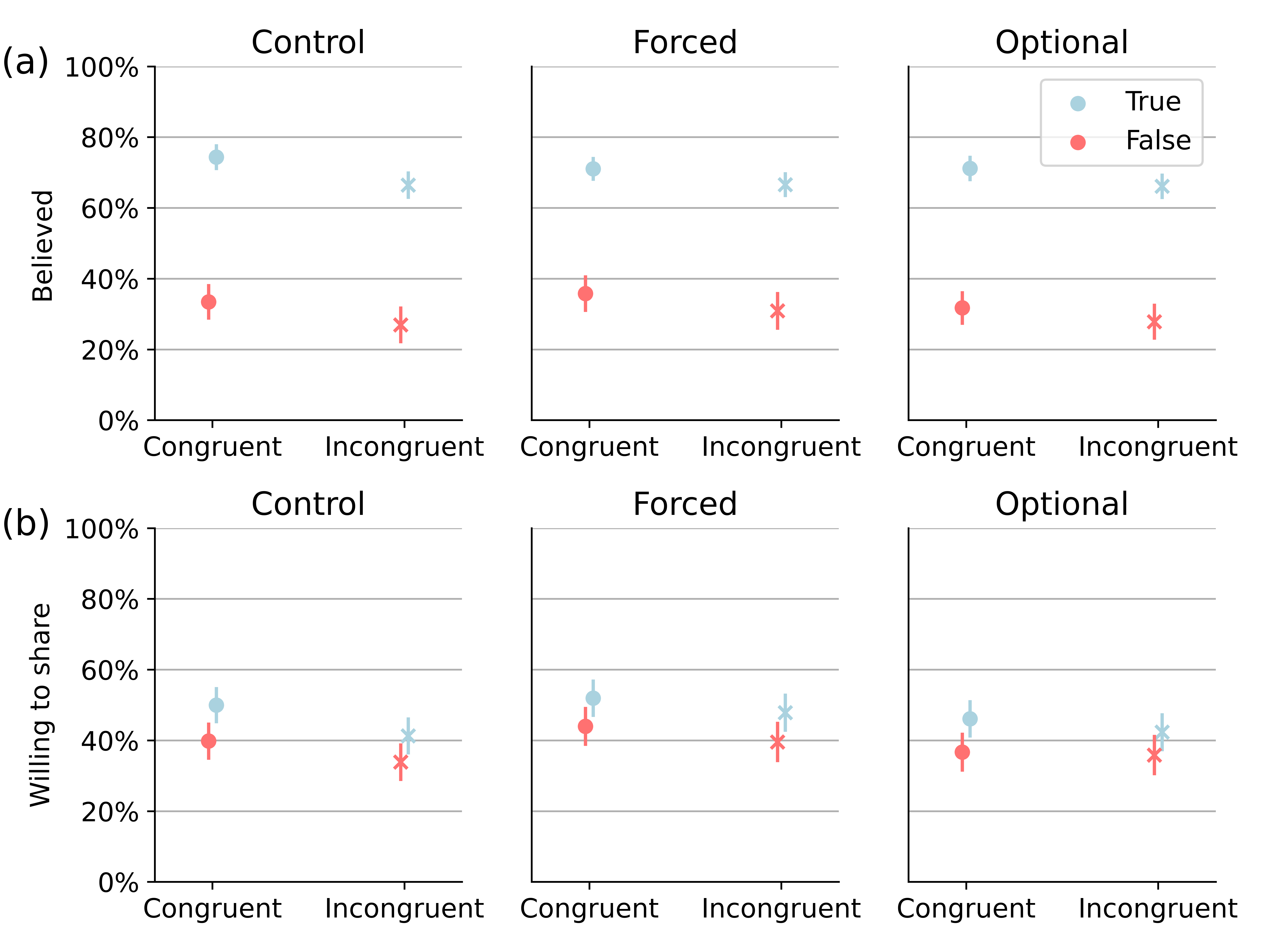
Fact-checking scenario (belief + congruency)
Fact-checking scenario (share + congruency)
Experimental Design (cont.)
Web prompt
I saw something today that claimed [HEADLINE TEXT].
Do you think that this is likely to be true?
Experimental Design (cont.)
Main effects
LLM-generated fact-checking information did not affect overall discernment
Human fact checks improve discernment